ETL (Extract, Transform, Load) is a common approach for integrating and moving data from source systems to analytics platforms. However, implementing and maintaining these solutions can be time-consuming and resource-intensive.
With Microsoft Fabric, there’s a better approach, Mirroring. It requires zero coding and minimal configuration to enable near real-time replication of data from Azure SQL Server to OneLake.
In this blog post, I’ll show you just how easy it is to configure mirroring in Microsoft Fabric.
What is Mirroring in Microsoft Fabric?
Mirroring in Microsoft Fabric is a no-code feature that enables seamless integration of external data sources into Fabric. With mirroring, you get near real-time data replication to OneLake, allowing you to access up-to-date information without complex ETL pipelines.
It is a fully managed service that uses Fabric’s compute to replicate data into OneLake. One of its biggest advantages is that it does not consume Fabric capacity during replication. Additionally, OneLake storage is free and for every Fabric Capacity Unit (CU), you get terabytes of storage. Fabric capacity is only used when you access the data, such as querying it.
Mirroring uses the Delta Lake table format, making the data instantly available to all analytics engines in Fabric through OneLake shortcuts. This simplifies data sharing across workspaces and teams while ensuring consistency.

Source: https://learn.microsoft.com/en-us/fabric/database/mirrored-database/azure-sql-database
Before configuring mirroring in Fabric, you need to have access to Azure SQL Database. However, there are some important limitations to consider when planning and enabling mirroring:
- Both Azure SQL Database and Fabric must be in the same Entra ID tenant
- The database must have a public endpoint. If a firewall is enabled, you need to allow Azure services in the Azure SQL Database logical server
- If you are using the DTU model, the database must have at least 100 DTUs
- Mirroring supports a maximum of 500 tables per database
- Mirroring can only be enabled in one Fabric workspace at a time
- Mirroring cannot be enabled if Azure Synapse Link for SQL or Change Data Capture (CDC) is already in use
Since these limitations may impact whether mirroring is feasible for your scenario, it’s important to plan ahead before enabling it.
Setting Up Azure SQL Database
In Azure, we need a logical SQL Server and a database to enable mirroring in Fabric. Before creating these resources, we first need to set up a security group for SQL administrators and a service principal that Fabric will use to access the SQL database.
Since Microsoft Entra-only authentication is recommend in Azure SQL, a service principal is required. Using Microsoft Entra ID identities instead of traditional username/password authentication is considered a best practice for security and automation.
To simplify deployment, we use Bicep to define and provision these resources. You can find the full code in my GitHub repository https://github.com/Matonen/blog-examples/tree/main/infra/bicep/stacks/fabric-mirroring.
With recent updates, Bicep now supports creating Microsoft Graph resources, allowing us to define all necessary resources for Azure SQL directly in Bicep. Using Microsoft.Graph, we can create a security group and a service principal like this:
var sqlAdminGroupName = 'SQL Server Admins'
resource sqlAdminGroup 'Microsoft.Graph/groups@v1.0' = {
displayName: sqlAdminGroupName
uniqueName: toLower(replace(sqlAdminGroupName, ' ', '-'))
mailNickname: toLower(replace(sqlAdminGroupName, ' ', '-'))
securityEnabled: true
mailEnabled: false
owners: [deployer().objectId]
members: [deployer().objectId]
}
var appName = 'sp-fabric-sql-statereader'
resource app 'Microsoft.Graph/applications@v1.0' = {
uniqueName: appName
displayName: appName
}
resource sp 'Microsoft.Graph/servicePrincipals@v1.0' = {
appId: app.appId
}The Bicep resource definitions above creates a security group and adds the identity that runs the deployment as an owner and a member.
Next we can create an SQL Server and a serverless database using custom Bicep modules. I prefer using custom Bicep modules because they are reusable and allow me to implement required configurations and best practices for the resources. You can find the full Bicep module definitions in my GitHub repository https://github.com/Matonen/blog-examples/tree/main/infra/bicep/modules/sql.
module sqlserver '../../modules/sql/server.bicep' = {
name: 'sqlserver'
params: {
name: 'sql-${solution}-${env}'
location: location
adminGroupName: sqlAdminGroup.uniqueName
allowedIpAddresses: allowedIpAddresses
}
scope: rg
}
module database '../../modules/sql/serverless-database.bicep' = {
name: 'database'
params: {
name: 'sqldb-fabric-mirroring'
location: location
serverName: sqlserver.outputs.name
}
scope: rg
}Once all resources are defined, we can easily deploy them using the Azure CLI command:
az deployment sub create --location westeurope --template-file main.bicepYou will be prompted to enter the required parameters during execution. Alternatively, you can specify them using the –parameters option, either with a parameter file or inline values. The command takes a few minutes to complete, but once the deployment is finished, you should see the resources in Azure.
Next, we need to create a server login for sp-fabric-sql-statereader. The required SQL commands are predefined in the create-server-login.sql file, which can be executed using the sqlcmd utility:
sqlcmd -S <your-server-name>.database.windows.net -d master -G -i create-server-login.sqlAfter that, we create demo tables and insert sample data into the sqldb-fabric-mirroring database by executing init-db.sql file:
sqlcmd -S <your-server-name>.database.windows.net -d sqldb-fabric-mirroring -G -i init-db.sqlAfter running the last command, the database is now set up with tables and sample data. In the Azure Portal, you can use the Query Editor for Azure SQL Database to verify the setup. The screenshot below shows the created tables along with an example query retrieving data from the database.
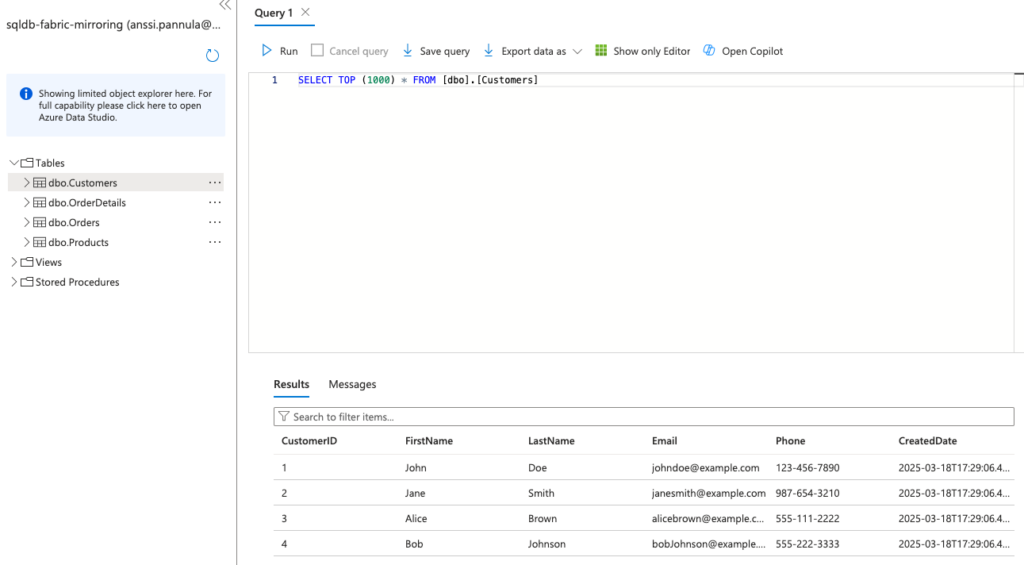
Now, the database is fully set up and ready to be mirrored to Fabric.
Creating a Mirrored Azure SQL Database in Fabric
Finally, open the Fabric portal and create a mirrored Azure SQL Database.
Navigate to your workspace, click New item, and search for the Mirrored Azure SQL Database item.
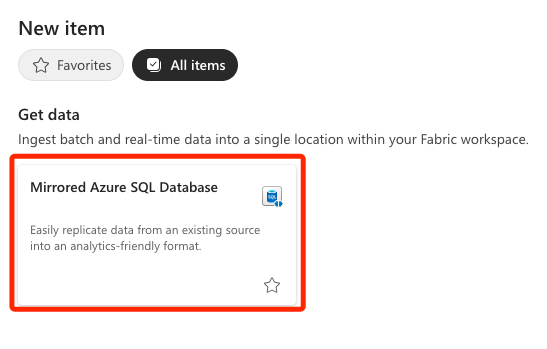
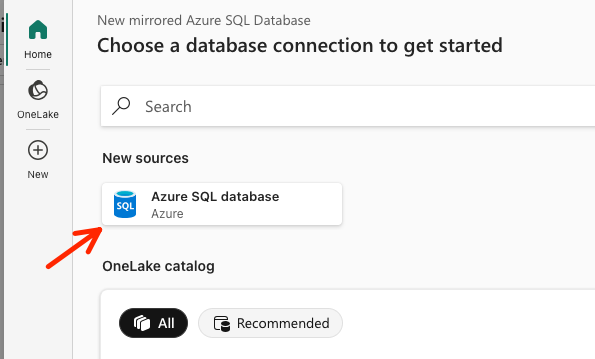
First, you need to create a new data source. Under New sources, click Azure SQL Database, which opens a new window where you can fill in the connection settings for your database.
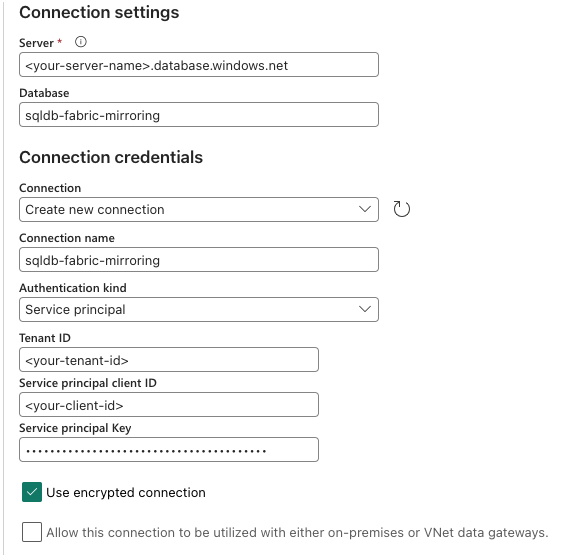
The Authentication type should be set to Service Principal. We previously created a service principal, so now we need to generate a secret for it. To generate a secret, use the following Azure CLI commands:
az ad app list --display-name sp-fabric-sql-statereader --query "[].appId" --output tsv
az ad app credential reset --id <id-from-previous-command> --display-name fabricThe credentials reset -command returns the App ID (client id), Tenant ID, and Secret, which need to be added to the connection settings.
After clicking the Connect button, you should see the newly created connection. Once selected, you can choose the tables you want to mirror. Select all tables and press Connect and create mirrored database.
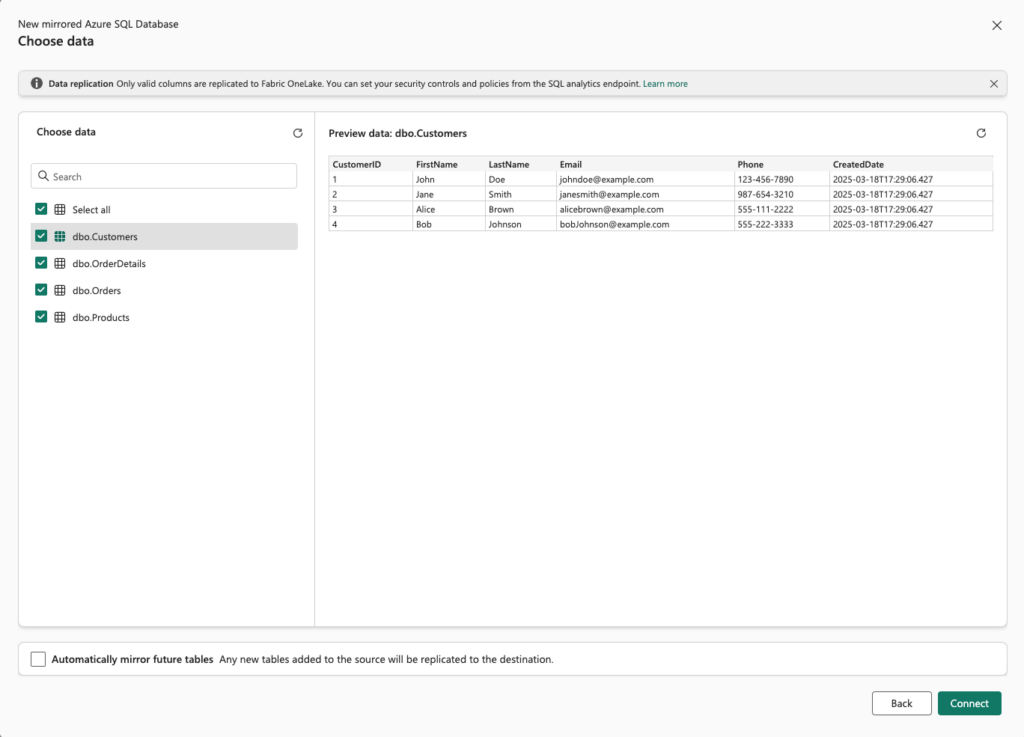
This will create three items in your workspace:
The SQL analytics endpoint offers seamless access to the replicated data, enabling you to query it easily using SQL.

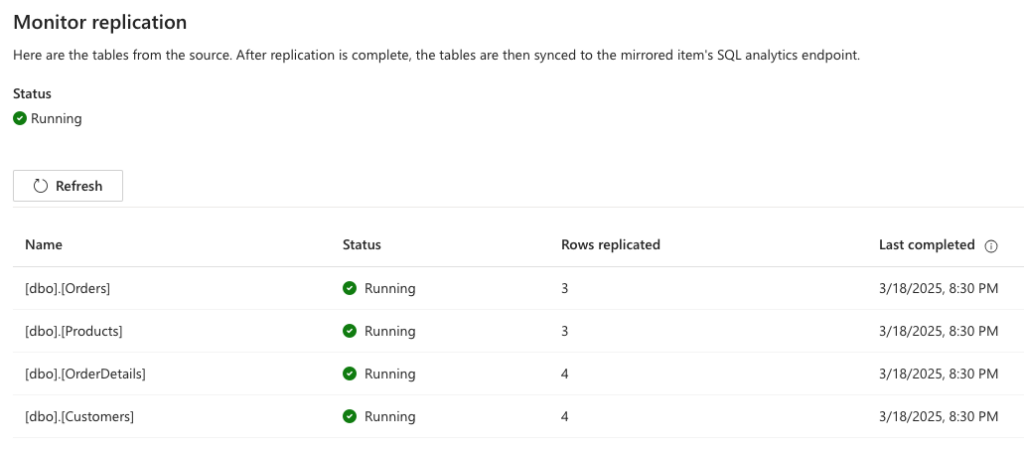
From the mirrored database item, you can easily monitor the replication status to ensure everything is running smoothly.
Summary
I’ve always preferred simpler, more efficient data solutions, and Azure SQL Mirroring in Fabric delivers exactly that.
Azure SQL Mirroring in Fabric enables real-time data synchronisation without the need for complex ETL processes, reducing latency and maintenance overhead. It ensures that data is always up to date in Fabric, making it ideal for analytics and reporting.
If you’re looking for a streamlined way to mirror your SQL data into Fabric, this guide will help you get started.